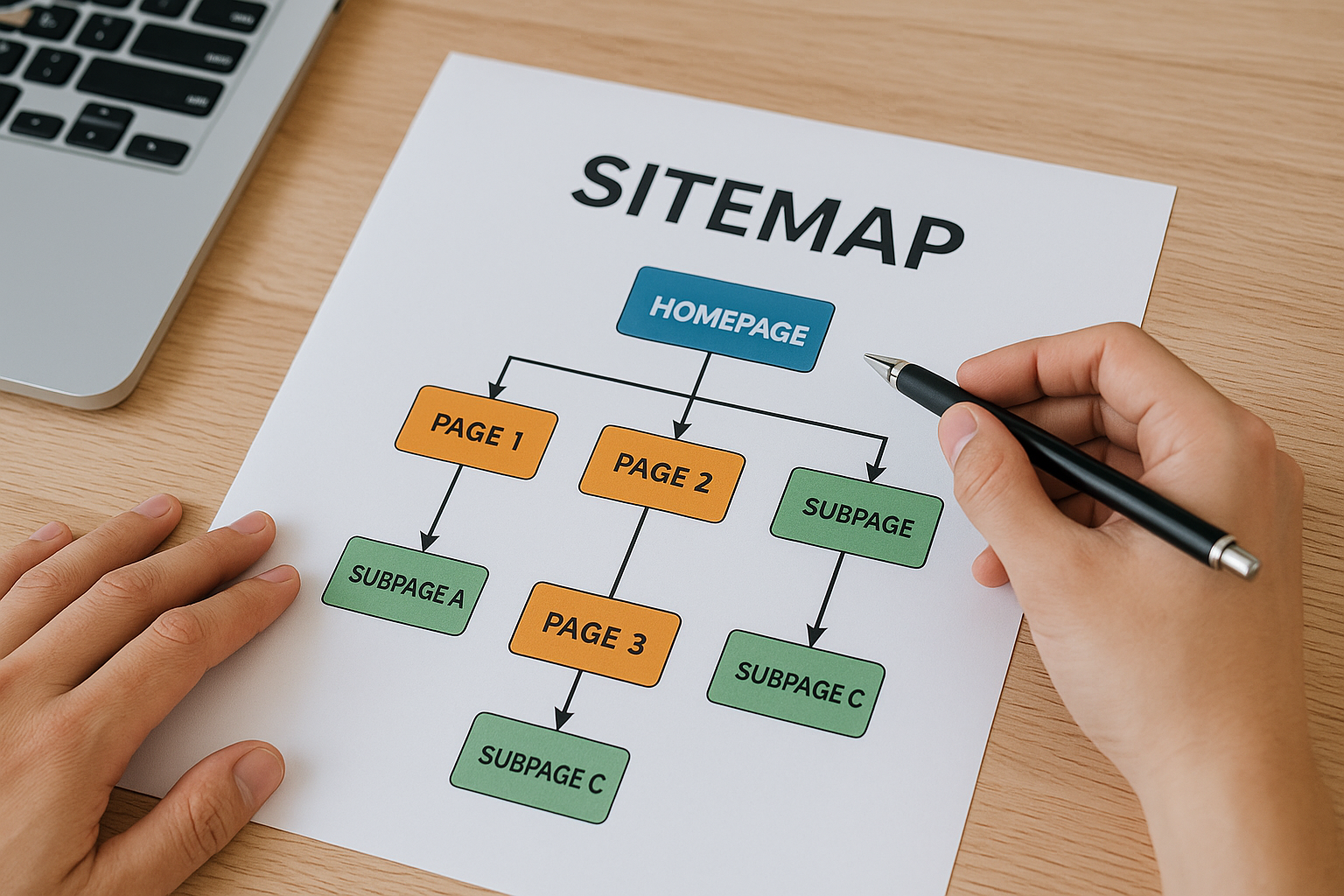
Mapa strony to coś więcej niż techniczny dodatek — to szybka wskazówka dla robotów wyszukiwarki, które adresy warto odwiedzić jako pierwsze. Gdy serwis rośnie, a struktura gęstnieje, plik sitemap pomaga Google dotrzeć do nowych podstron, nawet jeśli linki wewnętrzne nie prowadzą jeszcze wprost do celu. Takie wsparcie przyspiesza indeksację i skraca czas od publikacji do pojawienia się w wynikach — różnicę odczujesz zwłaszcza przy częstych aktualizacjach treści.
Nie każdy właściciel strony potrzebuje mapy, lecz staje się ona niezbędna, gdy witryna spełnia co najmniej jeden z poniższych warunków:
- sklep internetowy z tysiącami produktów i wielopoziomowym filtrowaniem,
- nowy blog, który dopiero zbiera linki zwrotne i ma słabe powiązania wewnętrzne,
- portal multimedialny pełen galerii oraz materiałów wideo.
Dzięki tej dodatkowej nawigacji roboty Google poruszają się sprawniej, a budżet crawl jest wykorzystywany efektywniej. W takich scenariuszach sitemap działa jak precyzyjna mapa skarbów, znacząco zwiększając szansę na pełne zindeksowanie treści.
Co ważne, przygotowując XML, pamiętaj, że Google od dawna ignoruje tagi i, skupiając się głównie na lastmod.
Regularne odświeżanie pliku — ręcznie lub za pomocą cron — gwarantuje, że każda aktualizacja trafi do wyszukiwarki bez zbędnej zwłoki.
W systemach takich jak WordPress zadanie przejmuje choćby Yoast czy wtyczka Semrush SEO, dzięki czemu Ty skupiasz się na treści, a nie na kodzie.
Dlaczego mapa strony jest warta zachodu?
Lepsza indeksacja nowych treści
Krótko po publikacji roboty wyszukiwarki szukają świeżych URL-i, ale w praktyce często trafiają na nie z opóźnieniem — szczególnie gdy struktura linków wewnętrznych jest skromna. Mapa strony podpowiada, które adresy pojawiły się właśnie teraz, dzięki czemu Google może je odwiedzić nawet kilka godzin wcześniej niż w modelu „tylko link”. Yoast zauważył, że aktualizacja znacznika w sitemapie jest dla algorytmu ważniejsza niż wiek linku zewnętrznego , a testy VisualSitemaps potwierdzają wzrost tempa indeksacji o kilkadziesiąt procent przy dużej liczbie zmian treści.
Aktualne atrybuty mają znaczenie
- Lastmod informuje o dacie modyfikacji i działa jak sygnał pilności.
- Priority oraz changefreq Google oficjalnie ignoruje, więc lepiej z nich zrezygnować.
Wsparcie dla złożonych serwisów
Sklep internetowy z tysiącami produktów i filtrami potrafi wygenerować setki wariantów URL, które nie zawsze są linkowane z menu. Mapa strony zapobiega pomijaniu takich kombinacji oraz tzw. sierot URL — podstron pozbawionych linków wewnętrznych. W efekcie kategorie, warianty kolorystyczne i opisy produktów trafiają do indeksu, a zawartość jest dostępna dla użytkowników szybciej. Dodatkowo każdy plik sitemap może obejmować maksymalnie 50 000 adresów lub 50 MB wagi; przy większym asortymencie tworzy się plik indeksowy, który porządkuje poszczególne części jak rozdziały w książce.
Przykłady zastosowania
- Portal newsowy utrzymuje osobną mapę News-Sitemap przechowującą tylko artykuły z ostatnich dwóch dni, co ułatwia pojawianie się w Top Stories.
- Serwis wideo korzysta z rozszerzenia Video-Sitemap, dzięki czemu miniatury i znaczniki czasu trafiają do wyników rich snippets.
Optymalizacja budżetu crawl
Google przydziela każdej domenie określoną liczbę żądań w ramach tzw. budżetu crawl; jeśli robot zużyje go na duplikaty lub parametry, ważne strony będą musiały poczekać. Sitemap kieruje uwagę bota na priorytetowe adresy, minimalizując straty i ograniczając ryzyko przeciążenia serwera. To szczególnie ważne, gdy plik robots.txt blokuje część zasobów lub gdy witryna korzysta z dynamicznych parametrów URL — w takich warunkach nagromadzenie bezużytecznych kombinacji może pochłonąć cały limit . Dodanie mapy w Search Console pozwala monitorować statystyki pobrań i natychmiast reagować na błędy 404 lub status “Couldn’t Fetch”.
Krótko mówiąc, pojedynczy plik XML staje się strategicznym planem, który ułatwia indeksację, wspiera skomplikowaną architekturę strony i oszczędza cenne zasoby crawla. Efekt to szybsza widoczność, pełniejszy indeks i mniej niespodzianek w raportach Search Console.
Rodzaje sitemap i ich zastosowania
XML vs RSS – kiedy co wybrać?
Pierwsza decyzja sprowadza się do tego, czy potrzebujesz pełnej listy wszystkich URL-i, czy raczej błyskawicznego sygnału o nowościach. XML sitemap obejmuje całą strukturę serwisu i może rosnąć do 50 000 adresów lub 50 MB; większe pliki dzielisz i łączysz w sitemap index, zachowując porządek bez utraty danych . RSS i Atom przekazują jedynie najświeższe wpisy, dlatego Google traktuje je jako uzupełnienie, przyspieszające wykrywanie nowych stron, lecz nie zastępujące klasycznego XML-a . Sam Google akceptuje RSS 2.0 i Atom 1.0 jako sitemap, co jest wygodne w popularnych CMS-ach – wystarczy podać adres feedu w Search Console, a robot sprawdza go nawet kilka razy dziennie.
Praktyczny przykład: magazyn online łączy oba pliki – XML dla całego archiwum oraz RSS ograniczony do 100 najnowszych artykułów, co pozwala Google pobierać bieżące treści kilka godzin po publikacji, a jednocześnie zachować dostęp do starszych wpisów bez dublowania zasobów.
Obrazy, wideo, newsy – rozszerzenia specjalistyczne
Rozszerzenia sitemap pozwalają dodać kontekst tam, gdzie zwykły URL to za mało. Każdy w Image Sitemap może zawierać do 1 000 tagów, co ułatwia indeksację galerii i zdjęć ładowanych zewnętrznymi skryptami . Video Sitemap wymaga miniatury, tytułu i opisu, a opcjonalne tagi (czas trwania, ograniczenia wiekowe) podnoszą szansę na bogate wyniki SERP; Google akceptuje też alternatywny format mRSS, przydatny przy strumieniowaniu. W świecie wiadomości króluje News Sitemap – tu obowiązuje limit 1 000 artykułów i 48-godzinne „okno świeżości”; starsze teksty trzeba przenieść do zwykłego XML-a, by uniknąć odrzucenia przez roboty.
Limity i organizacja
- Każdy z wymienionych formatów dziedziczy globalny próg 50 000 URL-i / 50 MB; większe zestawy dzielisz i spinasz plikiem indeksowym.
- Możesz łączyć rozszerzenia: ten sam URL w sitemapie obrazów może równocześnie występować w sitemapie wideo, co zwiększa pokrycie multimediów bez duplikacji struktur.
HTML Sitemap – przewodnik dla użytkowników
Choć nie jest skanowana tak intensywnie jak XML, HTML sitemap pełni rolę interaktywnego spisu treści i wzmacnia wewnętrzne linkowanie. Badania Semrush pokazują, że dodanie takiej strony zmniejsza współczynnik odrzuceń i przedłuża czas sesji, bo użytkownicy szybciej trafiają do głębokich podstron . W praktyce sprawdza się zwłaszcza w serwisach, gdzie główne menu nie obejmuje wszystkich kategorii – np. marketplace z setkami sekcji tematycznych. Wersja HTML poprawia również dostępność: odwiedzający z czytnikami ekranowymi zyskują kompletną mapę zawartości bez skomplikowanej nawigacji, co przekłada się na lepsze Core Web Vitals i pozytywne sygnały behawioralne.
Starannie dobrany typ sitemap – lub ich zestaw – pozwala więc obsłużyć zarówno rozbudowane archiwa, jak i natychmiastowe newsy czy wideo, maksymalizując widoczność każdej części witryny.
Automatyzacja i aktualizacja: kiedy robot robi robotę
Statyczny plik XML działa jak automatyczny drogowskaz dla botów, pod warunkiem że jest aktualny. Brak bieżących danych powoduje, że crawler widzi jedynie część zasobów, co przekłada się na straty ruchu i budżetu crawl.
Gdy witryna rośnie, ręczne dopisywanie linków staje się ryzykowne; łatwo zapomnieć o nowych podstronach, a nieusunięte 404-ki wywołują ostrzeżenia w Search Console . Dlatego automatyzacja generowania i zgłaszania mapy strony — od wtyczek w CMS-ie po zadania cron — skraca czas indeksacji i minimalizuje błędy strukturalne . Warto jednak zachować czujność redaktora: comiesięczny audyt pozwala wychwycić pętle przekierowań czy kanonikalizację, których skrypty nie zauważą.
Nie każda platforma potrzebuje identycznego workflow; dla bloga wystarczy feed RSS, ale sklep z milionem SKU wymaga zaawansowanego harmonogramu i podziału plików. W kolejnych podsekcjach znajdziesz scenariusze, które ułatwią dobranie właściwej strategii.
Generator w CMS a kontrola ręczna
W WordPressie Yoast SEO lub Rank Math uruchamia silnik sitemap w chwili publikacji wpisu, aktualizując znacznik bez udziału autora . Podobny efekt daje wtyczka XML Sitemap Generator, która obsługuje też obrazy i wideo, a poprzez harmonogram WP-Cron potrafi budować plik o zadanej porze doby .
Dla serwisów statycznych lub headless CMS sprawdzi się Screaming Frog SEO Spider: narzędzie crawluje witrynę, generuje mapę i zapisuje ją lokalnie lub zrzuca na serwer po zakończeniu procesu — wystarczy połączyć je z cronem, by całość odbywała się bez nadzoru. Manualna kontrola przydaje się przy migracjach; testowa mapa tworzona lokalnie pozwala sprawdzić strukturę przed wdrożeniem i uniknąć nagłego wysypu 404 w raporcie indeksu.
Harmonogram aktualizacji i powiadomień
Google po pierwszym sukcesie samodzielnie odświeża mapę według własnego rytmu, jednak znaczna przebudowa serwisu powinna kończyć się ręcznym Resubmit w Search Console, by skrócić czas reakcji botów. Jeżeli aktualizacje są częste, API Search Console pozwala wysłać żądanie PUT z adresem mapy bez logowania do panelu — minutowa operacja idealna do automatycznych pipeline’ów CI/CD.
Firmy korzystające z CDN-ów mogą hostować sitemapę na subdomenie (np. cms.example.com); ważne, by domena w linkach odpowiadała tej widocznej w pliku, inaczej robot może zignorować część URL-i . Wdrożenie kompresji .xml.gz skraca transfer, a Google bez problemu rozpakowuje taki plik podczas pobierania .
Lista kontrolna powiadomień:
- Cron lub GitHub Actions generuje i pakuje plik.
- Skrypt API wysyła ping do Search Console.
- Alert Slacka/Teams informuje o statusie 200 lub błędzie.
Limity 50 000 URL i 50 MB – jak je obejść?
Jeden plik sitemap nie może przekroczyć 50 000 adresów ani 50 MB w stanie nieskompresowanym; większe strony muszą dzielić listę i używać pliku sitemap index. Taki indeks może wskazywać do 50 000 kolejnych map, co daje teoretyczny milion londyńskich adresów bez utraty czytelności . Przy podziale warto grupować URL-e logicznie: produkty, wpisy blogowe, multimedia; dzięki temu w raporcie „Sitemaps” łatwiej zdiagnozować segment z problemem .
Zastosowanie wyżej opisanych rozwiązań pozwala utrzymać sitemapę w pełnej synchronizacji z treścią, a webmaster może skupić się na rozwoju serwisu zamiast na ręcznym dopisywaniu adresów.
Testowanie i zgłoszenie sitemap w Search Console
Krótki błąd w pliku sitemap potrafi zablokować indeksację setek stron, dlatego przed zgłoszeniem do Search Console warto przejść ścieżkę test → walidacja → ping.
Równocześnie poprawnie wysłany dokument otwiera raport „Sitemaps”, który pokazuje różnicę między liczbą przesłanych a zaindeksowanych adresów; ta metryka pozwala błyskawicznie wykryć problemy z kanonikalizacją, przekierowaniami i błędami 404.
Nie chodzi więc o jednorazową akcję, lecz o cykl kontroli jakości, który można zautomatyzować tak samo jak deployment aplikacji.
Walidacja online i lokalnie
XML-Sitemaps.com sprawdza składnię i natychmiast zgłasza niezamknięte tagi lub błędny namespace, a w razie powodzenia pozwala automatycznie pingować Google. Narzędziem konsolowym jest xmllint –noout –schema sitemap.xsd mapa.xml, które porównuje plik z oficjalnym schematem — szczególnie przydatne w pipeline CI/CD, bo zwraca kod wyjścia 0/1 . Dla sitemapy skompresowanej .xml.gz Google stosuje własny dekompresor, lecz zbyt agresywne opcje gzip bywają przyczyną komunikatu Compression errorw panelu GSC.
Błędy 404, pętle i kanonikalizacja
Google ostrzega, że każdy URL o statusie 404 w sitemapie zużywa crawl budgeti spowalnia skanowanie wartościowych stron. W raporcie „Stan mapy strony” trafiają one do kolumny Nieprawidłowy URL; szybkie usunięcie lub poprawne przekierowanie 301 skraca czas powrotu robota. Problematyczne okazują się także pętle 3xx — Search Console zwraca wówczas błąd Sitemap could not be read, mimo że plik pobiera się poprawnie lokalnie. Jeśli dołożysz niezgodny tag, raport pokrycia pokaże różnicę między Przesłano a Zaindeksowano, wskazując strony wykluczone przez kanoniczny duplikat.
Monitoring indeksacji po zgłoszeniu
Po poprawnym SubmitSearch Console własnym rytmem odświeża sitemapę, jednak API PUT /webmasters/v3/sites/{URL}/sitemaps/{feed} pozwala pingować indeks po każdym deployu — wygodne w GitHub Actions czy GitLab CI. W zakładce Sitemapsz najdziesz datę ostatniego pobrania, status i liczbę odkrytych adresów; gwałtowny spadek to sygnał do audytu pliku lub serwera (CDN potrafi zwrócić 403 dla Googlebota). Warto włączyć powiadomienia e-mail lub webhook Slacka, by alert Couldn’t fetch nie umknął w wakacyjnym sezonie.
Lista kontrolna przed naciśnięciem „prześlij”
- Walidacja online lub xmllintzwraca OK.
- Plik dostępny pod HTTPS 200 i nie wymaga logowania.
- Brak 404/soft 404 w raporcie pokrycia po pierwszym crawlu.
Stosowanie powyższego workflow gwarantuje, że mapa strony pozostaje precyzyjną nawigacją zarówno dla użytkowników, jak i botów, a niespodziewany zanik ruchu nie zaskoczy podczas poniedziałkowej kawy.
Najczęstsze pułapki oraz sposoby ich ominięcia
Najpowszechniejsze błędy techniczne
- Król wszystkich wpadek to umieszczanie URL-i nieprzeznaczonych do indeksu– stron z noindex, przekierowań 3xx albo kanonicznych wskazujących gdzie indziej. Google nadal pobiera taki adres, marnując budżet crawl.
- Tuż za nim plasują się odwołania do środowisk testowych(dev, staging). Wyciek jednego pliku sitemap potrafi zindeksować całą makietę i zduplikować treści w wynikach SERP.
- Trzecia grupa to błędy 404 i soft 404; każdy z nich pojawiający się w mapie odbiera robotom czas, który mogłyby przeznaczyć na wartościowe strony.
- Do tego dochodzą przekroczone limity (> 50 000 URL / 50 MB), źle zadeklarowany namespace czy sprzeczne znaczniki hreflang – wszystkie wykrywalne w raporcie „Sitemaps”, zanim uderzą w widoczność.
Historie z życia – case studies nieudanych wdrożeń
- Portalowi turystycznemu zablokowano całe katalogi noindex, lecz stary generator wciąż dopisywał je do sitemap; w efekcie Google co tydzień marnował tysiące żądań na niewidoczne strony, a nowe przewodniki pojawiały się w SERP-ach z kilkudniowym opóźnieniem.
- Sklep modowy dodał atrybuty hreflang w osobnej mapie, ale pomylił kody pli pt; algorytm potraktował to jak konflikt i obniżył ranking wersji polskiej na rzecz portugalskiej, co potwierdziła analiza w Search Console → International Targeting.
- Blogerka technologiczna przypadkiem opublikowała sitemapę z adresami staging.blog.pl, które kanonicznie wskazywały na produkcję; spowodowało to pętlę 3xx i widoczny spadek ruchu o 30 % w ciągu dwóch tygodni.
Szybkie sposoby naprawy i profilaktyka
Najskuteczniejszą tarczą jest automatyczna walidacja podczas deployu: xmllint lub wbudowany moduł CI przerwie publikację, gdy plik złamie schemat XSD albo przekroczy limit wpisów. Generator powinien filtrować tylko adresy 200 OK, kanoniczne i publiczne, aby URL-e z noindex lub 3xx nigdy nie trafiły do produkcyjnej mapy. W przypadku wersjonowania językowego lepiej trzymać hreflang w XML niż w kodzie HTML – łatwiej go wtedy audytować i wycofać przy błędzie, choć wymaga dyscypliny nazewnictwa kodów regionu.
Gdy serwis rośnie szybciej, niż planowano, ustaw task cron lub GitHub Actions do dzielenia pliku i aktualizacji indeksu; Google usprawiedliwia nawet 15 map w indeksie, byle każda mieściła się w wymaganiach rozmiaru i wagi. Na koniec monitoruj różnicę między „Przesłano” a „Zaindeksowano”; nagły skok wykluczeń sygnalizuje nową pułapkę wcześniej, niż pokażą to rankingi.








